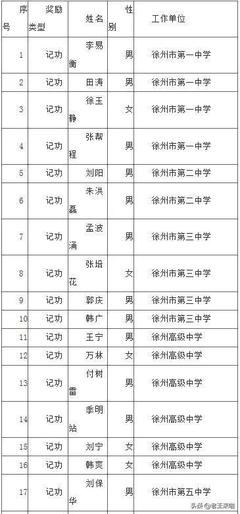
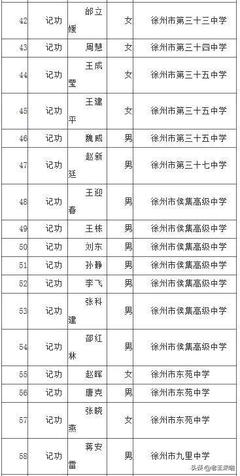
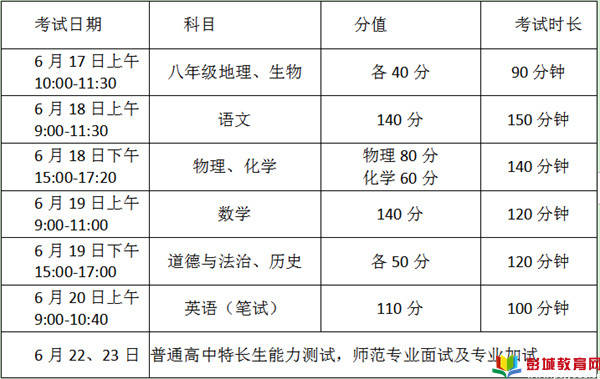
如若轉載,請注明出處:http://www.uniat.com.cn/product/47.html
更新時間:2026-04-01 00:35:25
----------------
地址:徐州市云龍區黃長路長山村委會綜合樓3-206室
電話:1392129**
Copyright © 2026 www.uniat.com.cn 徐州教育 徐州市蓓姬教育咨詢有限公司 徐州教育 版權所有 Sitemap